









Summary
These novel machine learning algorithms identify specific medication error types from patient safety event reports using natural language processing.
Inventors
Christian Boxley
Mari Fujimoto, PhD
Raj Ratwani, PhD
Allan Fong
What is it? What does it do?
Medication errors are events that lead to the mistaken use of medication by a patient or provider that can cause harm to a patient. While medication errors are one of the most frequently reported patient safety report types and represent high potential harm to a patient, they are also a mostly preventable event. The FDA states that they receive more than 100,000 medication error reports annually.
Patient safety event (PSE) reporting systems in hospitals have the potential to dramatically improve the safety and quality of care by exposing possible vulnerabilities, like medication error, before they lead to an adverse event. However, due to the large volume of reports and perceived level of patient harm, many safety reports go unanalyzed.
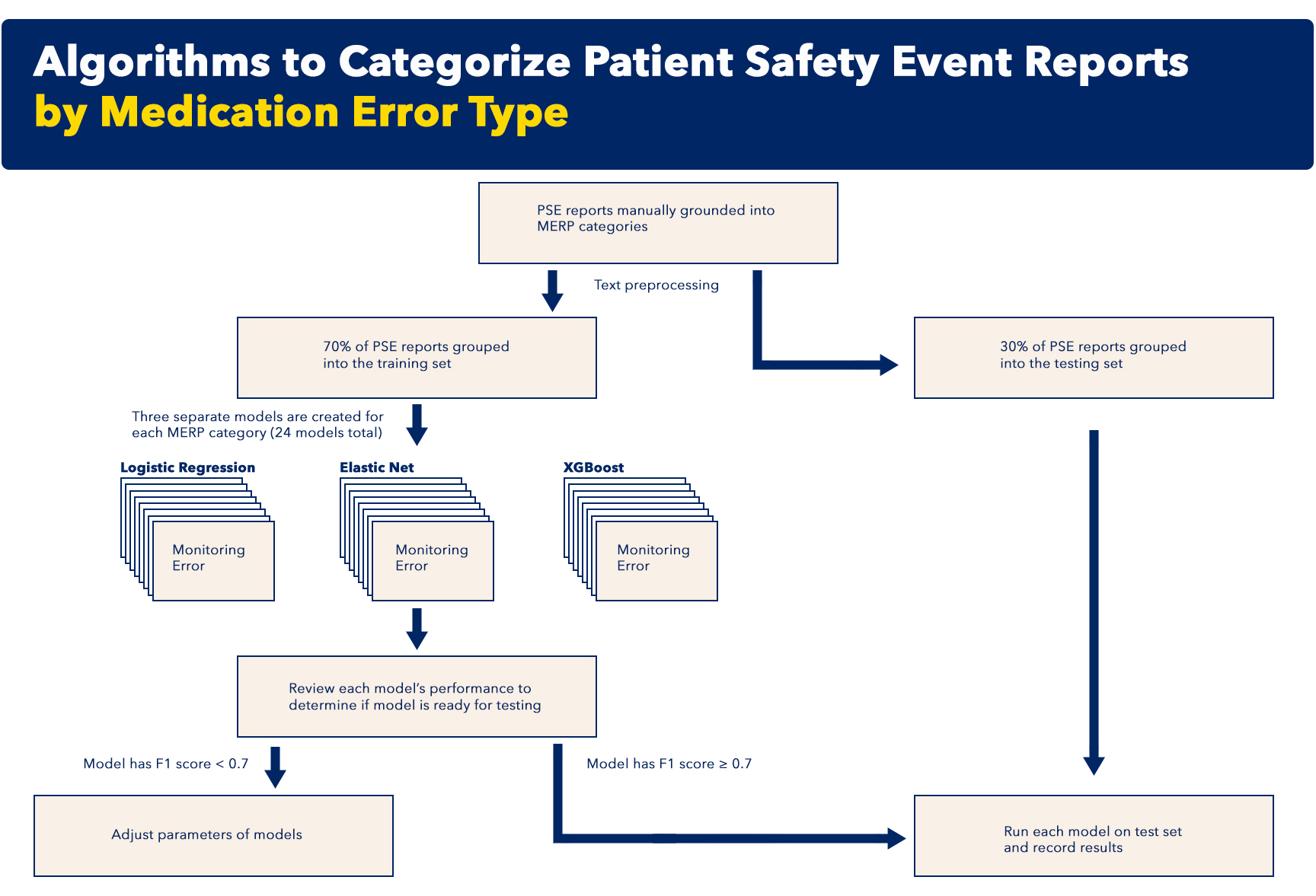
Using natural language processing (NLP), these novel machine learning algorithms can help uncover themes in PSE reports using a semi-automatic approach. By categorizing medication-related reports into eight modified National Coordinating Council for Medication Error Reporting and Prevention (NCC MERP) classifications by programmatically processing PSE reports, these algorithms bring coherent themes in medication error reports to light. This approach can improve the categorization of medication-related PSE reports, which may lead to better identification of important medication safety hazards.
Why is it better?
This novel approach to categorizing PSE reports by medication error will:
-
Save time and money by reducing manual review of PSE medication reports
-
Bypass the unreliability of the structured NCC MERP taxonomy and group reports by their free text to improve the accuracy of report classification
-
Have the potential to reduce adverse events related to medication errors through early identification of trends and emerging patterns in the PSE reporting system
What is its current status?
The NLP algorithms were developed, trained, and tested using about 3,000 PSE medication error reports from a mid-Atlantic, multi-hospital healthcare system. Using the NCC MERP standard taxonomy, eight modified categories were created to streamline and improve classification of the free text reports. Overall, precision performance was 0.86, specificity was 0.93, and model discrimination (AUROC) was 0.90 across all modified MERP categories. The five words most closely associated with each medication error category as well as medication error categories that were most likely to co-occur were also identified during the development of the algorithms.
The MedStar Inventor Services team is now seeking a licensing/collaboration partner to help advance and commercialize this technology. Please contact us at invent@medstar.net.
Related invention: